Data di dalam Big Data disimpan ke dalam data lake, yaitu tempat penyimpanan terpusat yang dapat digunakan untuk meyimpan semua data terstruktur maupun tidak terstruktur pada skala apapun yang dapat disimpan apa adanya tanpa memberi struktur pada data. Data-data tersebut dapat dikumpulkan atau dimasukkan menggunakan teknologi seperti Flume, Sqoop, Kafka, Apache Storm, Samza dan sebagainya.
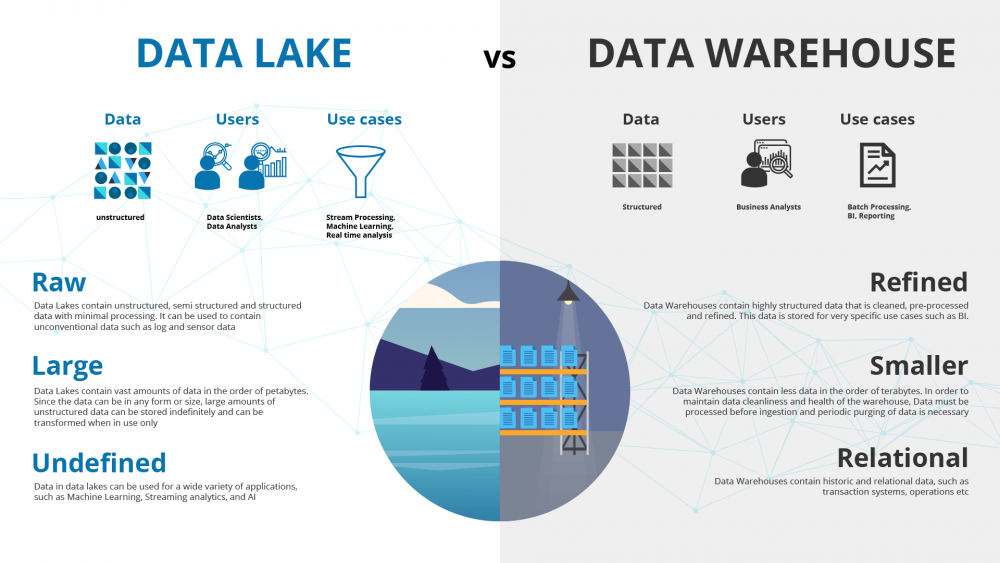
Data Lake
Berbeda dengan data Ware House yang merupakan mekanisme penyimpanan terstruktur, Data Lake dapat menyimpan data apa adanya, baik terstruktur, semi terstruktur maupun tidak terstruktur. Data lake cocok antara lain untuk proses streaming, machine learning dan real time analysis
— Flume, Sqoop dan Kafka: Mengumpulkan dan Memasukkan Big Data

Flume
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
https://flume.apache.org/
- Perangkat lunak ingestion (penyimpanan/memasukkan) untuk kapasitas besar
- Data berbasis event
- Memiliki 3 bagian utama
- source yang dapat berupa avro, exec, HTTP, JMS, Netcat, Spooling Directory, Syslog atau Thrift
- channel (1 source bisa memiliki banyak channel) yang dapat berupa file, JDBC atau memory.
- sink (1 channel 1 sink) yang dapat berupa Avro, File roll, Hbase, HDFS, Logger atau Thrift
Hubungan dengan https://pdsi.unisayogya.ac.id/administrasi-big-data-studi-kasus-hadoop/#hdfs adalah menggunakan channel file dan sink HDFS.
Sqoop
Apache Sqoop(TM) is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases. Apache Sqoop moved into the Attic in 2021-06.
https://sqoop.apache.org / https://attic.apache.org/projects/sqoop.html
- Perangkat lunak import export data dari RDBMS ke HDFS
- Dibuat menggunakan bahasa pemrograman Java
- Koneksi ke basis data melalui JDBC
- Dapat terhubung ke berbagai basis data
- Perintah berbasis command line
- Cara kerja:
- membaca struktur tabel
- mencari kunci primer dan membagi tabel berdasar kunci primer
- membuat map untuk menciptakan partisi job
Kafka
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
https://kafka.apache.org/
- Merupakan platform streaming terdistribusi
- memiliki mekanisme publish subscribe
- menjaga stream agar tidak hilang
- memproses stream secara real time
- Konsep
- Kafka berjalan pada kluster server yang terdistribusi
- Kluster kafka menyimpan stream baris data dalam kategori (topik)
- Setiap baris data terdiri dari key, value dan timestamp
- Penggunaan
- Menjadi penghubung antar sistem untuk data stream realtime
- Sebagai pemroses data stream realtime
- Sebagai penyimpan data

Pelatihan hari kedua dan ketiga Big Data Administration with Hadoop (3-4/8/2021) sebagai bagian dari penggunaan dana hibah PKKM tahun anggaran 2021 dengan mentor Nuzul Fauzan M (https://pdsi.unisayogya.ac.id/unisa-yogyakarta-menerima-bantuan-pemerintah-pkkm-tahun-anggaran-2021/). [bst]
Sumber:
2 replies on “Flume, Sqoop dan Kafka: Mengumpulkan dan Memasukkan Big Data”
[…] pelatihan pada https://pdsi.unisayogya.ac.id/administrasi-big-data-studi-kasus-hadoop/, https://pdsi.unisayogya.ac.id/flume-sqoop-dan-kafka-mengumpulkan-dan-memasukkan-big-data/ dan […]
[…] pelatihan pada https://pdsi.unisayogya.ac.id/administrasi-big-data-studi-kasus-hadoop/, https://pdsi.unisayogya.ac.id/flume-sqoop-dan-kafka-mengumpulkan-dan-memasukkan-big-data/ dan […]